
VGGNet (2014 - Very Deep Convolutional Networks For Large-sclae Image Recognition)
논문 링크 - https://arxiv.org/abs/1409.1556
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org
0. ABSTRACT

3x3 convolution filter를 사용하여 layer의 갯수를 증가시켰고, 이것이 large-scale image recognition에서도 좋은 결과를 얻게 만들었다
1. INTRODUCTION
앞에서 말한것 처럼 모든 layer에 3x3 Convolution Filter를 사용하여 Convolution layer를 추가함으로써 network의 깊이를 증가시켰다
2-1. ARCHITECTURE
INPUT DATA
- 224x224 RGB 이미지
Convolution Layer
- 3x3 Convolution Filter 사용
- 1x1 Convolution Filter 사용(선형 변환을 위해)
- stride = 1, padding = 1
- 5번의 max pooling(2x2에서 stride=2) 수행
- ReLU 활성함수 사용
Fc Layer
- Convolution layer를 지나서 3개의 FC layer층을 지남,
- 처음 2개는 4096 채널수를 갖고, 마지막에서 Soft-max layer 1000개 노드를 출력(ILSVRC 분류)
- ReLU 활성함수 사용
2-2. CONFIGURATIONS
A~E까지로 네트워크를 정의 (모든 구성은 일반적인 설계를 따르며, 깊이의 차이만 있음)
Convolution Layer의 채널수는 첫번째 Layer에서 64로 시작하여, max pooling마다 2배씩 증가하여 512에 도달
깊이가 늘어남에도 다른 네트워크들 보다 파라미터 수가 크게 늘어나지 않았음을 확인할 수 있다
(그러나 뒷단에 FC Layer를 사용하기에 여전히 많은 파라미터를 갖고 있다는 단점이 존재)
2-3. DISCUSSION
ConvNet 구성은 다른 sota모델들과 다르게 전체 네트워크에 걸쳐 매우 작은 3x3 receptive field를 사용
이는 여러 장점을 가져오게 됨

첫번째 장점
3x3 Convolution Filter를 2번 사용 == 5x5 Convolution Filter를 1번 사용
3개의 3x3 Convolution Filter를 사용 == 1개의 7x7 Convolution Filter를 사용
차이점은 3번의 3x3 Convolution Filter사용하면서 3개의 ReLU 활성함수를 거치게 되고,
이는 non-linear한 문제를 잘 해결할 수 있게 해주어, Conv Filter를 많이 사용하면
non-linear function인 ReLU를 더 많이 사용할 수 있는 장점이 있음
두번째 장점
3x3 Convolution Filter를 3번 사용하는 것이 7x7 Convolution Filter를 1번 사용하는 것 보다 파라미터 수가 줄어든다는 점이다(이렇게 줄어든 가중치들은 overfitting을 줄여주는데 도움을 준다)
3. CLASSIFICATION FRAMEWORK
3-1. TRAINING

Cost function - Multinomial logistic regression = Cross entropy
Batch size - 256
Optimizer - momentum(0.9)
Regularization - L2정규화(5.10^-4), Dropout(0.5)
Learning rate - 0.01 => validation error rate가 높아질수록 0.1배 감소시킴
AlexNet보다 더 깊고, 파라미터 수도 많지만 epoch는 더 적다
1. Implicit regularisation (2-3에서 언급한 것 처럼 3x3 Convolution Filter의 사용으로 인한 파라미터 수 감소)
2. Pre-initialisation
VGG A모델을 학습하고, 이후 모델을 구성할 때 A모델의 학습된 Layer를 가져와 사용하는 방식
최적의 초기값을 설정해서 학습에 더욱 용이함
Training image size

vgg모델을 학습시키기 위해 training image를 vgg모델의 input size에 맞게 바꾸어줘야함
1. s= 256으로 설정하면, training image의 w,h중 더 작은 것을 256으로 줄여준다
(이때 image의 비율은 유지하면서 나머지 비율도 rescailing을 진행 => isotropically-rescaled라고함)
2. isotropically-rescaled training image를 224x224 로 random crop 진행
s값을 설정하는 방식
1. Single-scale training 방식

s값을 256으로 설정하고 vgg모델을 학습시키고, 이때의 파라미터를 가져와 s=384로 변경하고 다시 학습을 진행
s=384로 설정하고 학습할 때는 learning rate를 줄여주고 학습을 진행
2. Multi-scale training 방식

s를 256~512범위로 랜덤하게 설정(이는 모두 제각각인 객체들을 학습하는데 학습효과가 좋아짐)
3-2. TESTING

Test image도 training image처럼 rescale과정이 필요
Test image rescale 기준값 Q 정의(Q는 S와 같을 필요는 없고, S값마다 다른 Q를 적용하면 vgg모델의 성능이 좋아짐)

rescaled Test image를 사용하는 test과정에서는 train과정에서의 vgg모델 구조를 변경하여 test를 진행
첫번째 FC Layer를 7x7 Conv Layer로 변경하고, 뒤의 2 FC Layer는 1x1 Conv Layer로 변경
(이로 인해 whole(uncropped) image에 적용 가능해짐)
FC Layer를 1x1 Conv Layer로 변경하는 과정에 대한 간단한 설명
기존에는 Flatten과정을 거쳐서 Conv Layer를 FC Layer로 변경하지만, 7x7x512에 7x7 Convolution Filter를 적용하게 되면 1x1x512의 Conv Layer형태로 바뀌게 되고, 이는 Flatten하는 과정과 동일하게 볼 수 있다(자세한 설명은 FCN 논문리뷰에서 진행)

그러면 FC Layer를 1x1 Conv Layer로 바꾸면 어떠한 것이 좋냐?
FC Layer의 경우 입력 노드가 파라미터로 정해져 있기에 입력 노드의 갯수가 동일해야 하고, 이로 인해 input image의 크기또한 고정된다. 그러나 Conv 연산에서는 이러한 제약이 없기에 최종 output feature map의 크기가 input image마다 다를것이다. 그렇다면 output feature map의 크기가 각기 다른 것을 어떻게 해결할 것인가?
이는 Global Average Pooling으로 해결하고 있다.

output feature map = 7x7x1000이라면, GAP을 거치고 나면 1x1x1000으로 바뀌게 되고, 이는 softmax를 거치고 flipped image와 original image의 평균값을 통해 최종 score를 출력하게 된다.
4. CLASSIFICATION EXPERIMENTS

Dateset으로는 ILSVRC를 사용했고, top-1 결과는 multi-class classification error, top-5는 ILSVRC에서 요규하는 기준을 사용
4-1. SINGLE SCALE EVALUATION

test를 진행할 때 image size가 고정되어 있는 것을 single scale라고 함
single scale training 방식에서는 Q=S로 고정하였고, multi-scale training 방식에서는 0.5(256+512)=384로 설정하였다고함

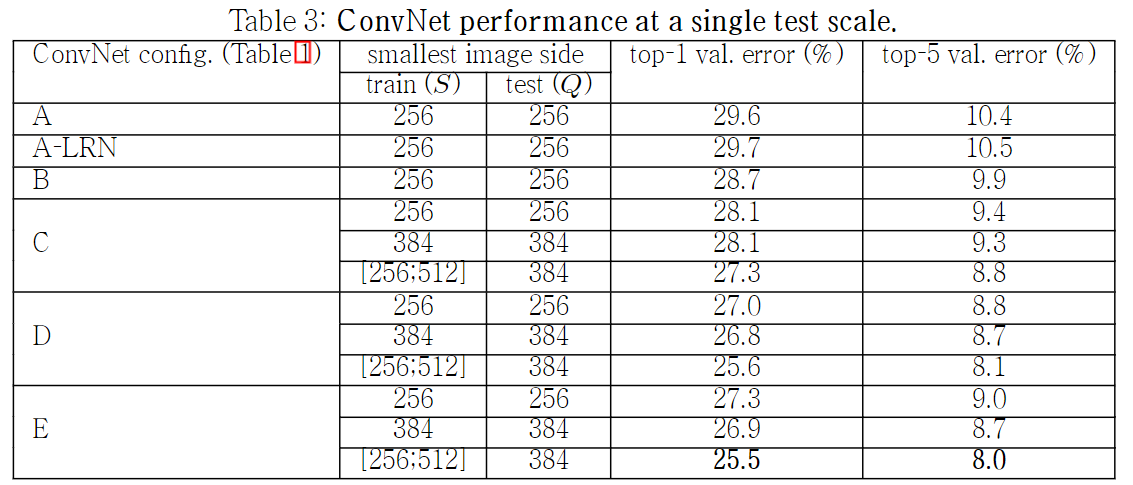
1x1 Conv filter를 사용하는 C모델 보다 3x3 Conv filter를 사용하는 D모델의 성능이 더 좋게 나왔다
그 이유는 1x1 Conv fliter는 non linearity를 잘 표현하지만, 3x3 Conv filter가 공간적 특징을 더 잘 포착하기 때문이라고 함
4-2. MULTI-SCALE EVALUATION


test 이미지를 multi scale로 설정하여 evaluation한것으로 하나의 고정된 S에 대한 여러 test image로 evaluation진행
4-3. MULTI-CROP EVALUATION

multi-crop evaluation방식과 dense evaluation의 평균으로 적절하게 섞은 새로운 방식인 ConvNet fusion으로 validation진행한 결과
4-5. COMPARISON WITH THE STATE OF THE ART
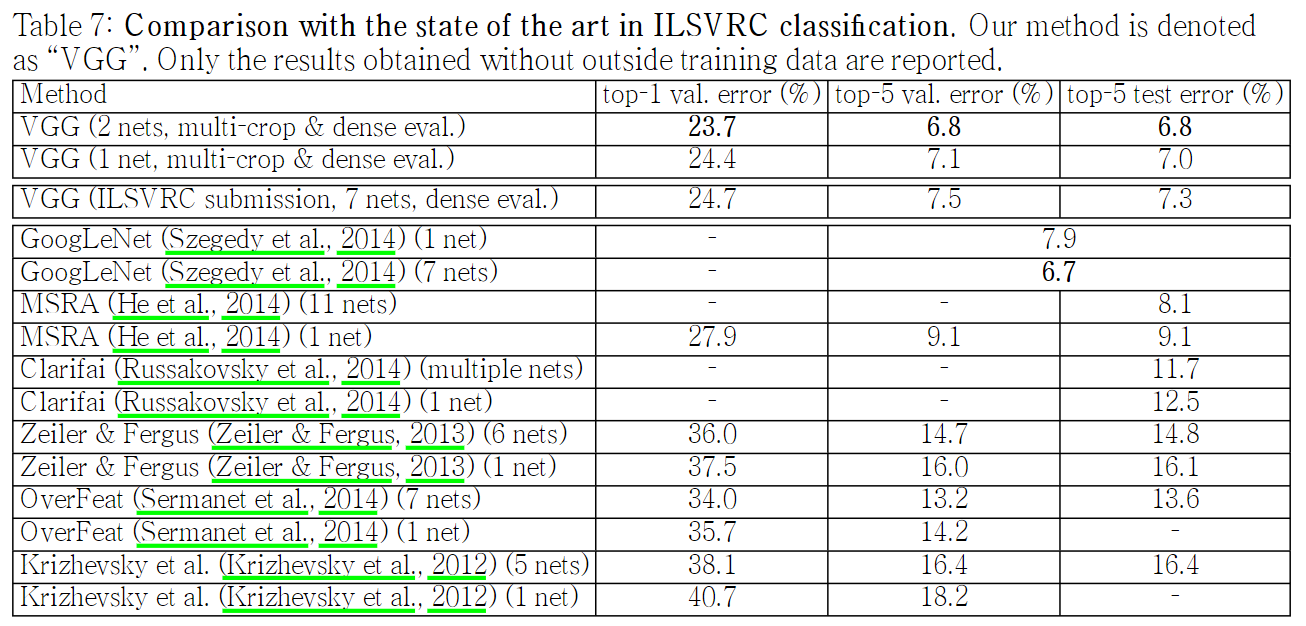
ILSVRC-2014 대회에서 VGG모델이 2등을 차지하였다
5. CONCLUSION

very deep convolution network에 대해서 알아보았다
representation depth가 분류의 정확도에 도움이 된다는 것을 확인할 수 있었고,
visual representation에서 depth의 중요성을 다시 한번 알 수 있는 실험이었다.
모델 구현
class VGG16(nn.Module):
def __init__(self):
super().__init__()
self.feature = nn.Sequential(
nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.MaxPool2d(2,2),
),
nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.MaxPool2d(2,2),
),
nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.MaxPool2d(2,2),
),
nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.MaxPool2d(2,2),
),
nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace =True),
nn.MaxPool2d(2,2),
),
)
self.fc_layer = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Linear(4096, 10),
)
def forward(self, x):
x = self.feature(x)
x = torch.flatten(x,1)
x = self.fc_layer(x)
return x참고 자료 출처
https://89douner.tistory.com/61