ResNet (2015 - Deep Residual Learning for Image Recognition)
논문 링크 - https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
0. Abstract
Deeper network의 train을 이전 네트워크보다 쉽게 할 수 있는 Residual learning framework을 제시
residual fuction은 Layer의 input을 참조하여 학습하는 방식으로 구성하였다.
Residual Network는 모델의 깊이가 깊어지면서 정확도도 상승하였다.
152개의 Layer를 쌓은 모델은 VGG모델보다 복잡도가 낮았다.
1. Introduction
feature의 level은 stacked layer의 깊이로 풍부해진다
ImageNet에서 좋은 성능을 보인 모델들은 16~30층의 깊이를 가진 deep 모델이다
그러면 여기서 이러한 질문을 할 수 있다
Layer를 깊이 쌓을수록 더 쉽게 모델의 학습이 가능할까?
이 질문에 대해 두가지 장애물이 존재한다
1. Convergence 문제
vanishing/exploding gradient으로 문제 발생, 이는 학습 초기 수렴을 방해
normalized initialization과 normalization layer를 이용하여 문제를 다룸
backpropagation, stochastic gradient descent를 통해 10개의 layer는 수렴이 가능해짐
2. Degradation 문제
모델의 깊이가 증가할수록 accuracy가 포화되고, 성능저하가 발생함
이러한 성능저하 문제는 overfitting에 의한 것이 아님
layer 추가할수록 training error가 높아지는 것을 확인
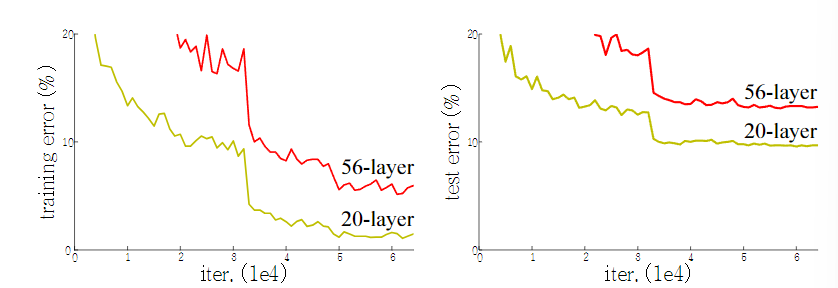
이는 Figure 1을 통해서도 확인이 가능함
test error만 봤을 때는 overfitting을 생각할 수 있지만,
training error도 56-layer가 나쁘기에 overfitting이라고 볼 수 없음
논문에서는 Degradation문제를 해결하기 위해 deep residual learning framework를 소개함
Underlying mapping을 H(x)라고 하면, H(x)를 학습하는 것보다
Residual mapping F(x)=H(x) - x 를 학습하게 하는 것이 좋다는 가설을 세움
(즉, residual mapping을 0으로 만드는 것이 쉽다)
F(x)+x는 shortcut connection을 가진 feed forward network라고 할 수 있음
shortcut connection은 하나 이상의 layer를 건너뛰는 연결을 말하고,
Identity mapping을 수행하여 이를 layer의 출력에 추가하는 역할을 함
Identity shortcut connection은 파라미터나 연산의 복잡성을 증가시키지 않음
모델은 여전히 SGD와 backpropagation으로 end-to-end 학습이 가능함
Degradation문제를 해결하기 위한 residual learning방법을 증명하기위해 다음의 2가지를 증명할 것
1. deep residual net은 최적화가 쉽지만, plain net은 깊이가 증가하면 더 높은 training error 발생
2. deep residual net은 깊이가 증가해도 Accuracy 향상을 이루어 내어, 이전 모델보다 좋은 결과를 도출
3. Deep Residual Learning
3-1. Residual Learning
H(x)를 few stacked layer의 underlying mapping이라고 함
F(x) = H(x) - x 일 , H(x) = F(x) + x 를 opimize하는 것으로 학습하는데 용이함
이러한 재구성(residual learning reformulation)은 identity mapping이 opimial하다면,
nonlinear layer의 파라미터를 0으로 설정하여 identitiy mapping에 근접할 수 있음
3-2. Identity Mapping by Shortcuts
Residual block을 Figure 2의 형태이고, 식(1)과 같이 정의하였다
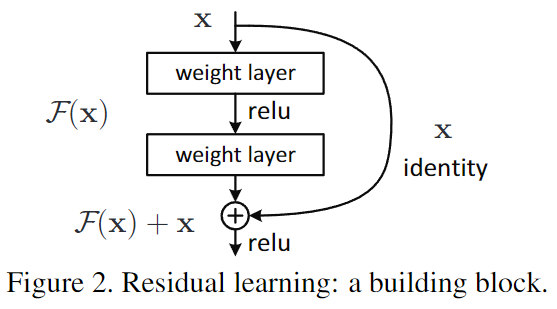

식(1)에서의 x와 y는 layer의 입력과 출력이고, 함수 F(x,{w})는 학습할 residual mapping을 의미
F + x 연산은 shortcut connection을 의미하고,
element-wise addition진행 후, Nonlinear function을 거친다
이러한 shortcut connection은 추가 파라미터나 계산 복잡성을 유발하지 않는다는 장점을 갖고 있고,
이것이 다른 plain 모델과의 차이점이다

식(1)에서 x와 F의 dimension이 다르다면, 식(2) linear projection을 수행하여 dimension을 일치
Residual function F는 더 많은 layer를 사용할 수도 있다.
그러나 F가 1개의 layer만 있다면, 이는 linear layer와 비슷하여 이점을 갖지 못한다
3-3. Network Architectures
Plain network와 Residual network를 테스트한 결과를 비교한다

Plain Network
VGG 네트워크에서 영감을 받았다
Residual Network
34-layer plain network shortcut connection을 추가
input, output의 dimension이 같다면 식(1)을 사용
dimension이 다르다면 2가지 옵션이 존재
(A) shortcut은 identity mapping을 수행, zero padding을 진행하여 dimension 일치
(B) 식(2)의 projection shortcut을 수행
3-4. Implementation
Input image - ImageNet을 사용할 때, [256, 480] 범위 내에서 더 짧은쪽의 길이로 resizing
224x224크기(input image size)로 random하게 crop
Horizontal Flip을 사용하여 Data augmentation 진행
Batch Normalization - Conv filter 연산과 activation function 사이에 적용
Optimizer - SGD
Batch size - 256
learning rate - 0.1로 시작하여 error가 수렴할때 마다 0.1배씩
weight decay - 0.0001
momentum - 0.9
4. Experiments
4-1. ImageNet Classfication
1000개의 class로 이루어진 2012 ImageNet Dataset으로 실험을 진행

Plain Network
Figure 4를 보면 plain-34 모델이 training error가 더 높은 것을 볼 수 있는데,
이러한 optimization difficulty는 vanishing gradient에 의해 발생하는 것이 아니라고 주장
그 이유는 BN을 통해 forward propagated signal이 0이 안되게 보장,
BN으로 healthy norm을 보여주는 backward propagted gradient를 증명
깊은 Plain network가 아주 작은 convergence rates를 갖고 있어서
training error가 약하게 줄어든다고 추측
Residual Network
Figure 4를 보면 ResNet-34가 ResNet-18보다 더 깊은 네트워크임에도 training error가 낮음을 알 수 있다
이를 통해 ResNet에서 Degradation problem을 피할 수 있게 되었다는 것이 확인 가능하다

Plain 모델과 비교를 해봤을 때, residual learning방식을 적용하면
더 깊은 layer를 쌓고, 더 좋은 성능을 낸다는 것을 알 수 있다
마지막으로 Figure 4를 참고하여 18-layer plain/residual 모델들을 비교해봤을 때,
정확도는 비슷하지만, ResNet이 더 빠르게 최고 성능에 Convergence 하는 것을 확인할 수 있다
Identitiy vs Projection Shortcuts
parameter free, identity shortcut이 training을 돕는 것을 확인했기에
Projection shortcut에 대한 조사를 진행
(A)옵션 - 증가하는 차원에 대해 zero-padding shortcut 적용
(B)옵션 - 증가하는 차원에 대해 Projection shortcut, 그렇지 않으면 identitiy shorcut 적용
(C)옵션 - 모든 경우에 Projection shorcut 적용
A보다 B가 조금 더 좋음 -> (A)는 zero padding이 residual learning이 없기 때문
B보다 C가 조금 더 나음 -> Projcetion shortcut에 의해 도입된 추가 파라미터 때문
A/B/C의 차이가 작다는 것은 Projection shortcut이 Degradation 문제를 다루는 데 중요한 요소가 아님을 알 수 있음
Deeper Bottleneck Architecture
training time을 감당하기 위해 Deeper network에서는 빌딩블록을 Bottleneck 구조로 변경

residual function F를 2개가 아닌 3개의 layer을 사용
각각 1x1, 3x3, 1x1 Convolution으로 구성
1x1 Layer는 차원의 크기를 조절하는 역할을 수행
3x3 Layer는 input/output의 차원을 작게 만드는 역할을 수행
Bottleneck 구조가 Layer가 1개 많지만, 시간 복잡도는 비슷하다
만약 identity shortcut이 projection shortcut으로 바뀐다면
shortcut이 두 고차원에 연결되어 있기에, 시간 복잡도와 모델의 크기는 두배가 된다

결과적으로 152개의 Layer를 쌓은 ResNet-152의 성능이 제일 좋은 것을 확인할 수 있고,
Layer가 깊어질수록 더 좋은 성능을 보인다는 것을 알 수 있다
참고 자료 출저
https://wandukong.tistory.com/18