FCN (2015 - Fully Convolutional Networks for Semantic Segmentation
논문 링크 - https://arxiv.org/abs/1411.4038
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build
arxiv.org
0. Abstract
end-to-end, pixels-to-pixels로 trained된 Convolutional network가
semantic segmentation분야에서 SOTA 달성
임의 크기의 입력을 받아 동일한 크기의 output을 내는 Fully convolutional network를 구축
기존 classification 모델(VGGNet)을 fully convolutional network로 바꾸고,
fine-tuning하여 deep layer에서 의미적인 정보를 추론하고,
shallow layer에서 형태 정보를 추론하여 둘을 혼합하여 사용
1. Introduction
픽셀 단위 예측을 위해 end-to-end supervised pre-training방식을 활용한다
동일한 크기의 output을 출력하기 위해 upsampling 기법을 활용
이미지의 deep, coarse한 의미적 정보와 shallow, fine한 외관 정보를 결합하기 위해 skip 구조 정의
3. Fully convolutional networks
3-1. Adapting classifiers for dense prediction
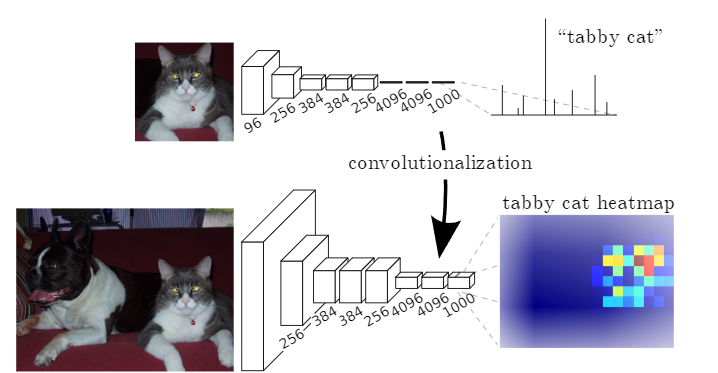
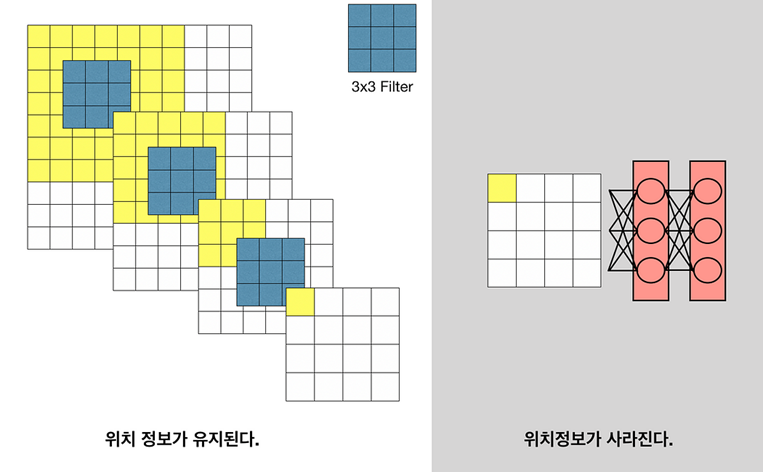

기존 classification 모델들은 고정된 크기의 input을 받아 nonspatial output을 출력한다
FC layer는 고정된 dimension을 가지고, spatial 정보를 버리게 된다
(위 그림처럼 FC layer를 거치면 분류 class의 확률값을 출력하기에 이미지의 공간적 정보를 버리게 된다)
논문에서는 FC layer를 kernel을 사용한 convolution 연산으로 대체하여
모든 크기의 입력을 받아 classification map을 출력하는 Fully convolutional network로 변환한다
FCN은 전체 이미지를 받아 효율적인 계산량을 가지게 된다
4. Segmentation Architecture
4-1. From classifier to dense FCN

classification task에서 좋은 성능을 보인 VGG16모델을 FCN으로 변경
1x1 Convolution 연산을 사용하여 FC layer를 대체
4-2. Upsampling is backwards strided convolution
4-1과 같은 convolutionalization 과정을 거친 Feature map은 총 5번의 Pooling layer를 지나서 원본 크기의 1/32의 size를 갖게 되고, 이 과정에서 정보 손실이 발생하여 이후 stride = 32로 up-sampling한 dense map은 여전히 coarse하기에 좋은 성능을 갖지 못한다
이로 인해 convolutionalization 과정에서 pooling을 덜 거친 중간 feature map들을 활용하는 skip architecture를 제안
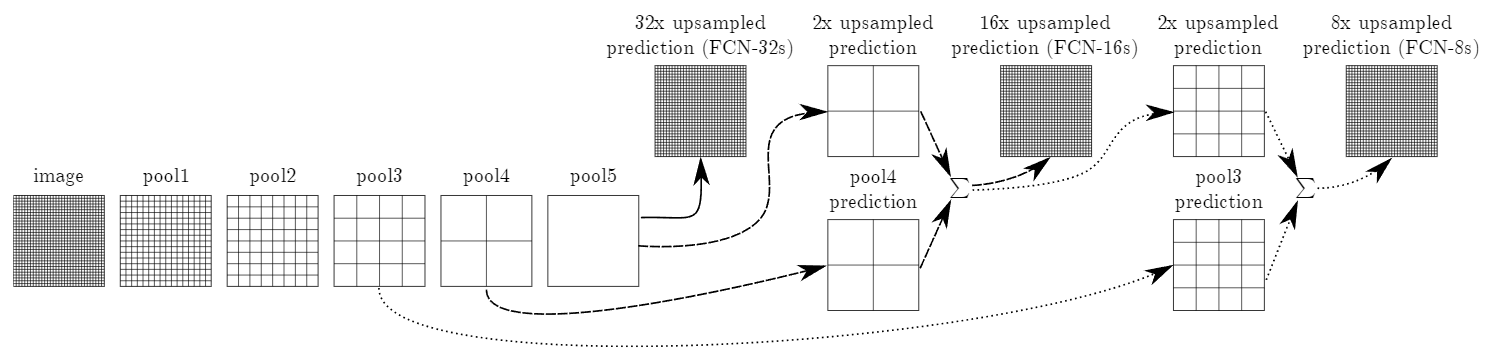
skip architecture의 구조는 간단하다
CNN은 얕은 층에서는 낮은수준의 특징을 포착하고, 깊은 층에서는 복잡하고 포괄적인 정보를 포착한다
이러한 직관을 기반으로 5번의 pooling layer를 거친 dense map과 convolutionalization과정에서 pooling layer를 거치기 전의 얕은 층의 feature map을 결합하면서 up-sampling을 진행하여 성능 향상을 이루어 냈다
FCN -32s => 최종 dense map에 stride = 32인 up-sampling을 진행한 결과
FCN -16s => 최종 dense map에 stride = 2인 up-sampling을 진행하고,
이를 4번의 pooling을 거친 feature map과 결합한 뒤, stride = 16인 up-sampling을 진행한 결과
FCN -8s => 최종 dense map에 stride = 2인 up-sampling을 진행하고,
이를 4번의 pooling을 거친 feature map과 결합하고, stride =2인 up-sampling을 진행,
이를 3번의 pooling을 거친 feature map과 결합한 뒤, stride = 8인 up-sampling을 진행한 결과

Figure 4는 각각의 모델들이 segmentation을 수행한 결과를 보여준 output이다
stride =32로 up-sampling을 진행한 FCN-32s보다 pooling feature map과 결합한 FCN-8s이 더욱 자세하게 segmentation을 수행한 것을 확인할 수 있다.
Table 2는 각 모델의 성능을 보여준다
여기서도 당연하게 FCN-8s가 제일 좋은 성능을 나타낸 것을 확인할 수 있다
6. Conclusion
Fully Convolutional Network는 classification model을 segmentation task에 맞게 수정한 모델이다
Fc layer를 convolution layer로 변경하니 학습과 추론이 단순화되고, 속도를 높이면서, 성능까지 향상시킬 수 있었다