CS231n 7강
이번 강의에서는 지난 6강에 이어 Neural Network의 training에 대해서 배웁니다.

지난 강의에서 우리는 최솟값 Loss를 찾기 위해 Optimization을 사용한다고 배웠습니다. 위 슬라이드는 Gradient descent를 사용하여 Loss가 최적화되는 과정을 시각화한 것이며, 우리의 최종 목적은 빨간 지점에 도달하여 최소 Loss값을 갖는 w를 찾는 것입니다.

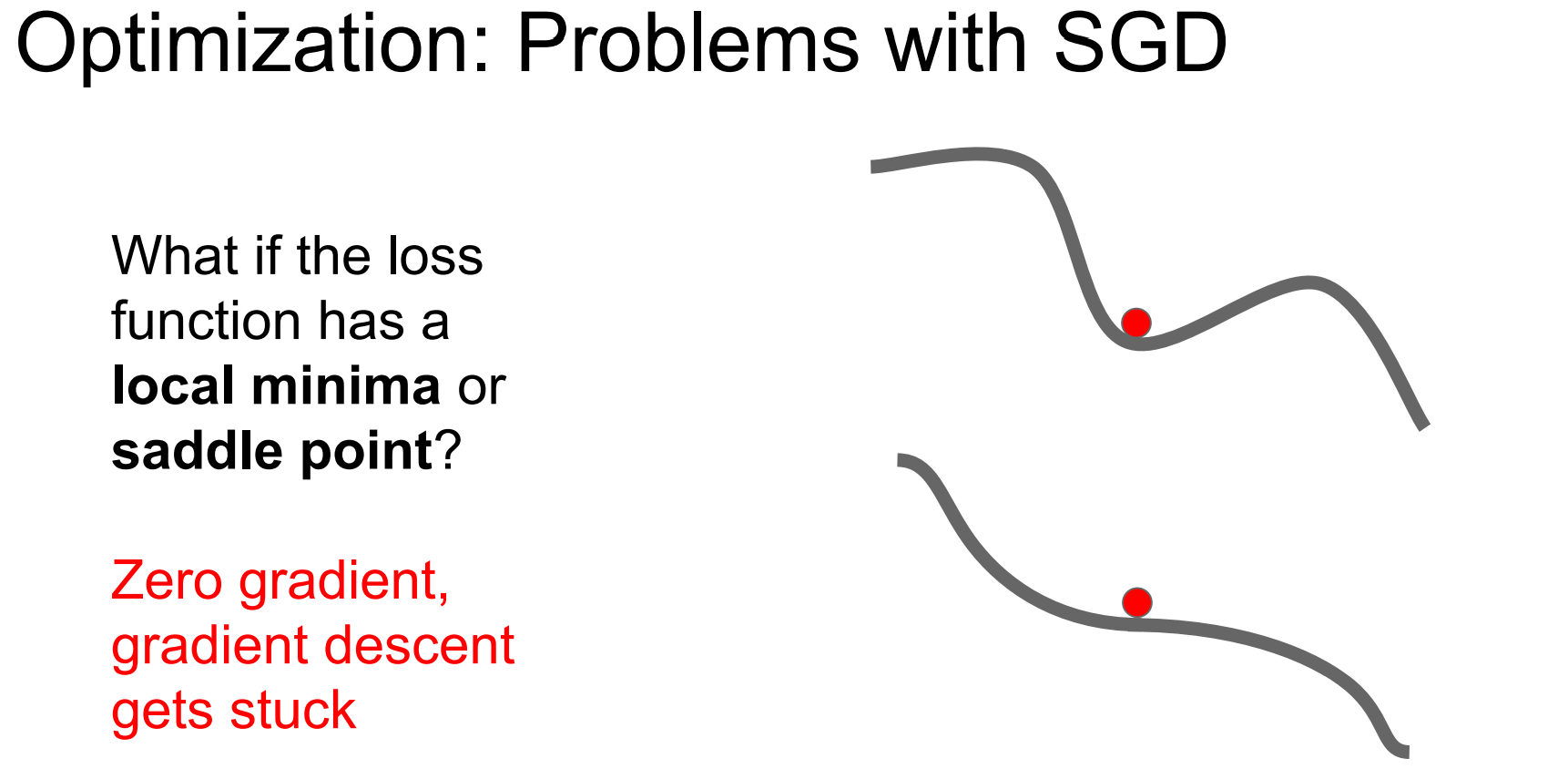
우리가 배웠던 SGD는 문제점을 갖고 있습니다. 왼쪽 슬라이드에서 우리는 빨간점에서 시작하여 최적점을 찾아갈 때, Loss가 수직적으로 예민하여 지그재그로 이동하게 되고, 이는 수렴속도가 느려지게 만드는 문제를 만듭니다. 추가로 오른쪽 슬라이드와 같이 Local minimum에서도 기울기가 0이라 이를 global minimum으로 착각하여 학습을 중단하는 문제와 saddle point와 같이 기울기 0의 주변 지점에서도 기울기가 매우 작아 updata가 매우 느려지는 문제가 발생합니다. 이번 강의에서는 SGD의 문제를 해결할 방법에 대해서 소개합니다.

SGD + Momentum입니다. 이는 gradient가 updata되는 방향에 대한 가속도를 유지하여 local minimum과 saddle point를 지나가게 하는 방법입니다. gradient에 대한 방향과 velocity에 대한 방향을 합쳐서 update함으로써 noise를 줄여주는 효과를 얻습니다.


다음은 Nesterov Momentum입니다. 이는 gradient방향과 velocity방향을 계산하여 원점에서 출발하는 momentum의 update방식과 달리 velocity방향을 우선 update하고, gradient방향을 update함으로써 momentum보다 빠르다는 장점을 얻습니다. 오른쪽 슬라이드를 보면 Momentum과 Nesterov가 더 빠르고, velocity로 인하여 overshotting이 발생한다는 것을 알 수 있습니다. 하지만 Nesterov는 현재와 old velocity의 차이를 더해주기에 Momentum보다 overshotting이 덜 발생한다는 차이점이 있습니다.

다음은 AdaGrad입니다. 이는 기울기의 제곱값을 이용합니다. 기울기의 제곱값을 update step에서 나누어주어 small gradient의 경우 속도가 잘 붙는다는 장점과, large gradient의 경우 wiggling dimension을 slowdown해서 천천히 내려온다는 장점을 가져옵니다. 하지만 update 경향이 작아지는 경우 학습이 멈출 수 있다는 단점이 있습니다.
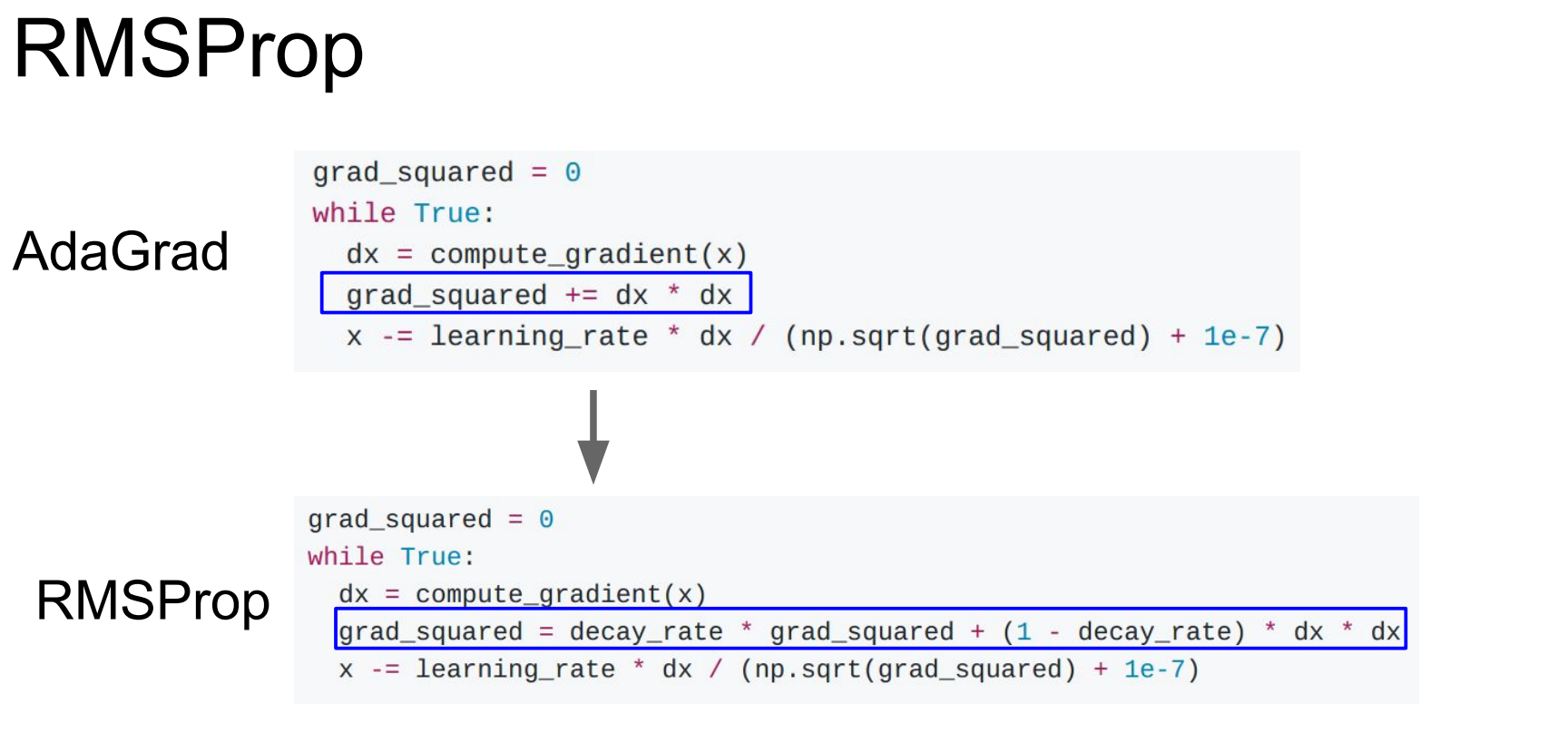
다음 RMSProp은 AdaGrad와 달리 decay_rate를 추가로 반영하여 update경향이 작아지는 것을 약간 해소해준다고 합니다.
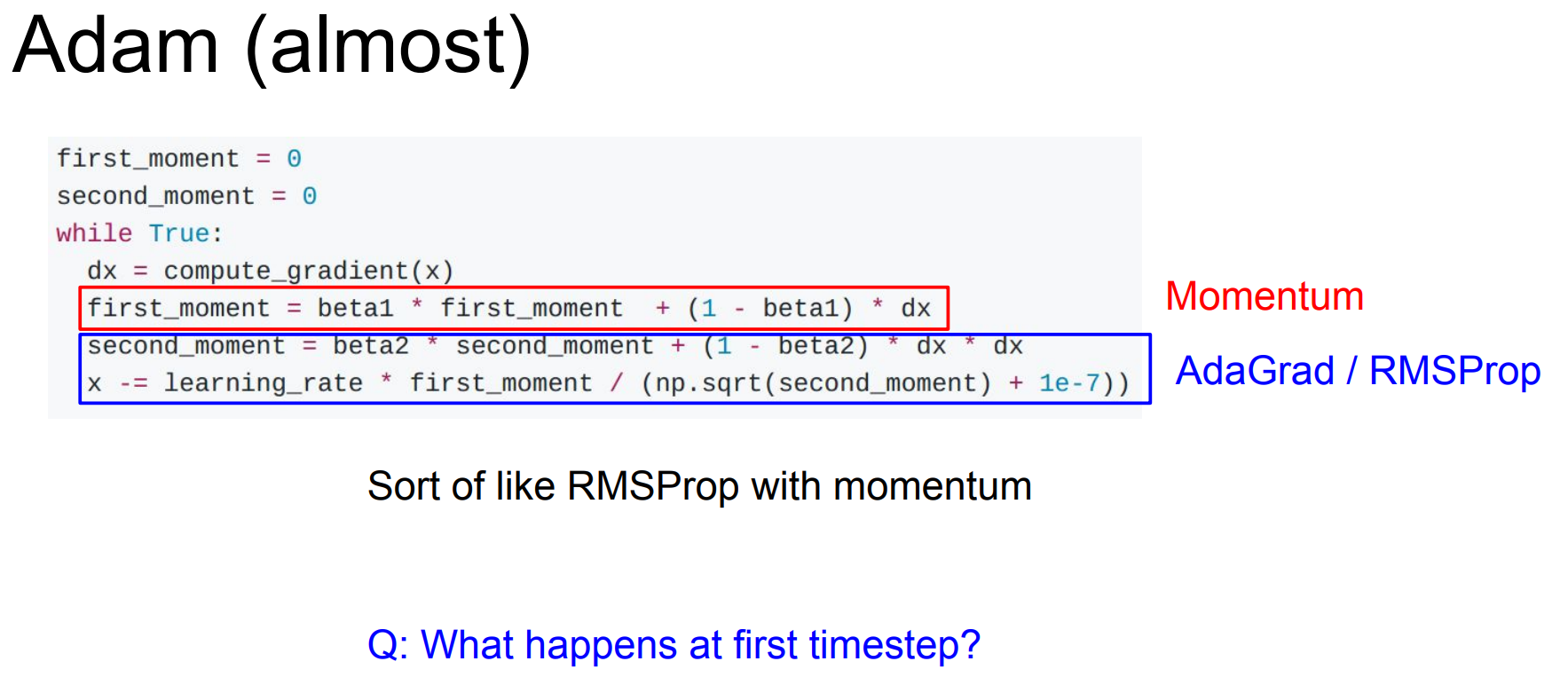

다음은 Adam입니다. 이는 Momentum의 velocity아이디어와 RMSProp의 update경향 반영 아이디어를 결합한 방식입니다. 오른쪽 슬라이드를 보면 Adam의 성능이 좋다는 것을 알 수 있습니다.

다음은 모델의 성능을 향상시킬 수 있는 방법들에 대해 배웁니다. 그중 먼저 배울 성능향상 방법인 앙상블에 대해 알아봅시다. 앙상블은 여러 독립적인 모델들을 train하고, test시에 여러 모델들의 평균을 결과값으로 채택하는 방식입니다. 앙상블은 과적합을 방지하고, 1,2%의 성능개선을 해줍니다.

앙상블에 대한 tip으로는 모델을 여러개 만들고 train하는 것이 많은 시간,비용이 필요하므로 하나의 모델을 학습 도중 지점을 저장해서 이를 평균내는 방식이 있습니다.
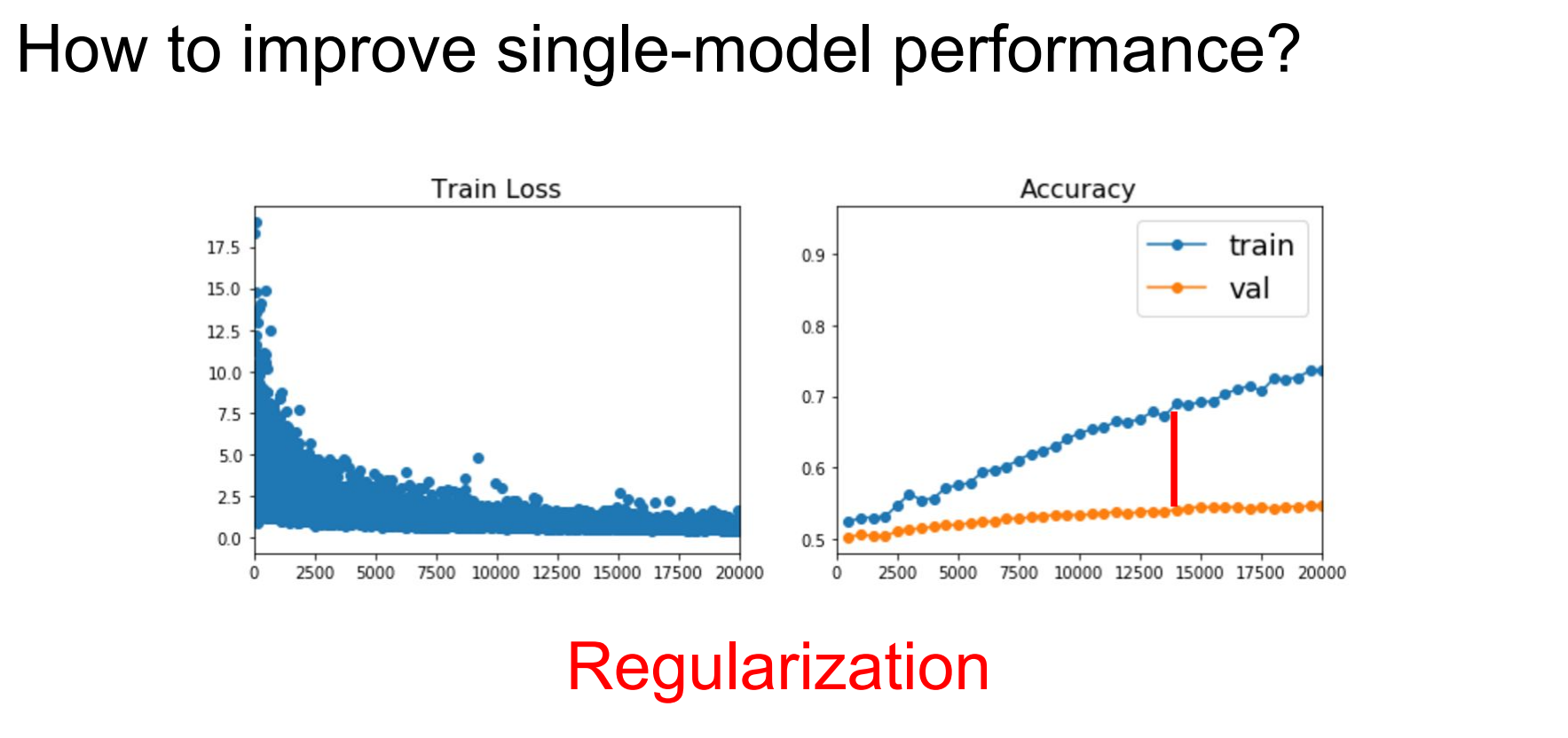
위 슬라이드의 오른쪽 그래프를 보면 과적합이 발생한 것을 알 수 있습니다. 과적합은 모델성능을 하락시키는 요소입니다. 그리고 우리는 지난 강의에서 과적합을 줄이는 방식으로 규제항을 추가하는 것을 배웠습니다.

우리가 배웠던 L1, L2 방식은 NN에서는 쓰이지 않고, Dropout방식의 규제를 사용하여 모델의 성능을 향상시킬 수 있습니다. 이는 Layer의 몇몇 뉴런을 랜덤하게 죽여버리는 방식입니다. 고의로 일부 뉴런의 출력값을 0으로 만듦으로서 특정 feature를 감지하는 뉴런의 영향력을 줄여 과적합을 방지하게 만드는 효과를 얻습니다.

다음 규제 방법은 Data Augmentation입니다. Data Augmentation은 train이미지의 Label은 유지한채로 이미지의 변형을 가하여 학습을 진행시키는 것을 말합니다.
규제 방법으로는 위와같은 것들이 있지만 보통 Batch Normalization을 사용하고, 과적합이 발생한다면 dropout을 추가해준다고 합니다.

다음은 Transfer Learning에 대해서 배웁니다. Transfer Learning은 ImageNet과 같은 큰 크기의 dataset으로 학습을 시키고, train된 모델을 사용자가 원하는 작은 크기의 dataset에 적용시켜 좋은 성능을 얻는 방법입니다. 모델에서 최종 class score를 출력하는 Fc Layer를 초기화 시키고, 작은 dataset의 class갯수에 맞게 모델 구조를 수정합니다. 그리고 나머지 Layer를 freeze시키고, 작은 dataset의 학습을 진행시킵니다. 데이터의 양에 따라 train될 Layer를 조정해주는 fine tuning을 고려해봐야 하고, 이미 잘 학습된 모델이기에 Learning rate는 작게 설정하면 좋습니다.

dataset의 크기와 dataset의 유형에 따라 4가지 경우의 수가 나옵니다.
1. 학습된 모델이 갖고 있는 Label이 많고, dataset이 작은 경우
Linear Classifier를 마지막 Layer로 사용한다.
2. 학습된 모델이 갖고있는 Label이 많고, dataset이 큰 경우
적은 Layer를 fine-tuning한다.
3. 학습된 모델이 갖고있는 Label이 적고, dataset이 작은 경우
No답,,
4. 학습된 모델이 갖고있는 Label이 적고, dataset이 큰 경우
많은 Layer를 fine-tuning한다.