YOLOv8 Custom Dataset 학습
Local 환경에서 YOLOv8 Custom Dataset을 학습시키는 과정을 기록으로 남겨두려고 합니다.
1. Custom Dataset 다운로드
Detection Dataset으로 유명한 Roboflow를 이용하였습니다.
Dataset은 Aquarium Dataset을 사용하였습니다.
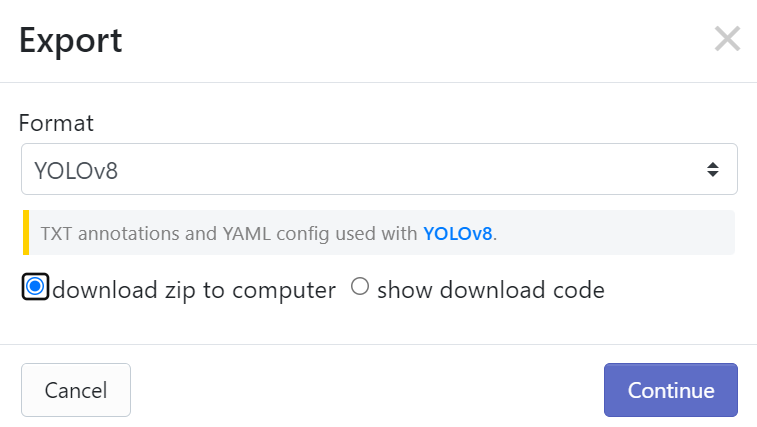
위의 링크로 접속하여 오른쪽 상단의 Download 버튼을 클릭한 후, YOLOv8 Format을 눌러 다운로드를 진행합니다. Dataset은 train, test, valid 폴더로 이루어져 있고, 각각의 폴더는 images와 labels로 구성되어 있습니다. 이를 진행하고자 하는 프로젝트 폴더에서 datsets이란 폴더를 생성하여 압축을 해제해줍니다.
2. Custom Data를 위한 yaml파일 생성
YOLO모델은 yaml파일을 참고하여 data를 학습합니다. Custom Dataset을 학습하기 위해서는 Custom Data에 맞는 yaml파일을 만들어주어야 합니다. 저는 가상환경을 따로 만들어 로컬에서 작업을 진행하였고, 이를 위해 PyYaml 패키지를 설치해주었습니다.
!pip install PyYAML
이후 Custom Dataset의 내용에 맞는 Aquarium_Data.yaml파일을 생성해주었습니다.
import yaml
data = { 'train' : './train/images/',
'val' : './valid/images/',
'test' : './test/images',
'names' : ['fish', 'jellyfish', 'penguin', 'puffin', 'shark', 'starfish', 'stingray'],
'nc' : 7 }
with open('Aquarium_Data.yaml', 'w') as f:
yaml.dump(data, f)
with open('Aquarium_Data.yaml', 'r') as f:
aquarium_yaml = yaml.safe_load(f)
display(aquarium_yaml)
3. YOLOv8 설치
다음으로는 YOLOv8 모델을 위한 셋팅을 진행하겠습니다. YOLO 설치 방법은 2가지가 있습니다.
- git clone을 이용하여 github의 파일을 가져오는 방법
- pip install을 통해 패키지 형태로 불러오는 방법
저는 Local환경에서 가상환경을 만들어 진행을 하였기에 2번 pip install방식을 선택하였습니다.
!pip install ultralytics
이후 설치한 패키지에서 YOLOv8모델을 불러와 model을 선언합니다.
import ultralytics
ultralytics.checks()from ultralytics import YOLO
model = YOLO('yolov8n.pt')print(type(model.names), len(model.names))
print(model.names)
4. Train
다음음 이전 단계에서 불러온 model과 Aquarium_Data.yaml파일을 이용하여 Train을 진행합니다.
❗이때, 주의할 사항이 있습니다❗
Ultralytics를 설치하게 되면, settings.yaml파일이 설치되는데, 해당 파일에 datasets_dir 파라미터를 아래와 같이 변경해주어야 이후 진행할 train과정에서 오류가 발생하지 않습니다.
datasets_dir: C:\...\yolov8(본인이 진행하는 프로젝트 파일명)\datasets(custom datasets파일명)
만약 settings.yaml 파일을 못찾으신 분들은 해당 내용을 참고하시면 도움이 될 것 같습니다.
power shell을 켜서 아래와 같이 command를 작성하면, settings.yaml파일이 보이게 됩니다😊
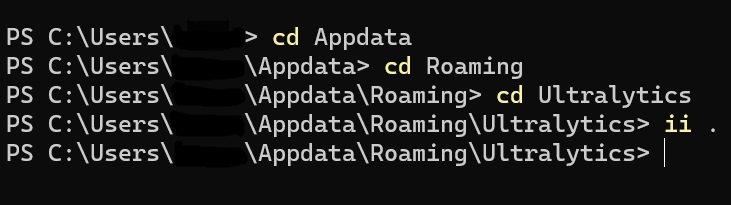
settings.yaml파일의 datasets_dir 파라미터를 수정하였다면, model train을 진행합니다. 이때, data를 제외한 나머지 파라미터는 본인이 원하는 값으로 수정하면 되고, 본인의 gpu를 활용하여 train을 진행하고 싶으신 분들은 'workers=0'으로 설정해주시면 됩니다.
model.train(data='Aquarium_Data.yaml', epochs=100, patience=30, batch=32, imgsz=416, workers=0)
학습이 완료되면, runs/detect/train 파일에 학습에 대한 다양한 정보들이 저장된 것을 확인할 수 있습니다.
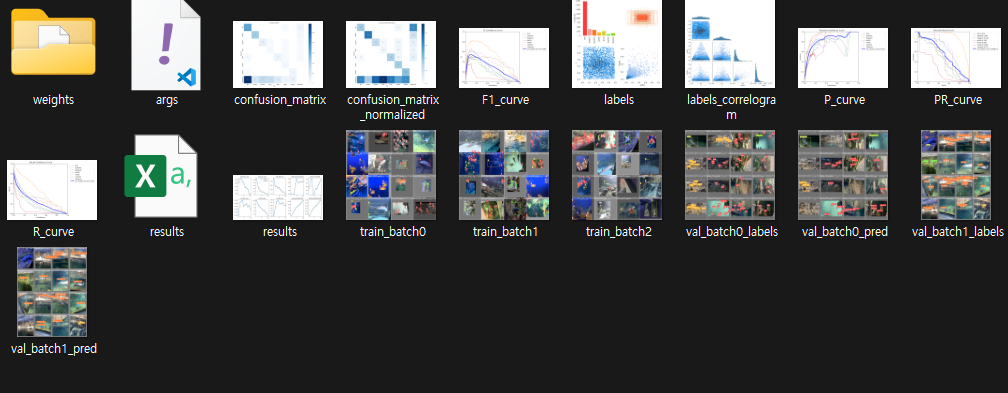
5. 학습한 weight를 이용하여 test 진행
Test데이터에 대한 infer을 하기전에 간단한 이미지를 이용하여 infer을 진행해봅니다.
model = YOLO('runs/detect/train/weights/best.pt')
model.predict(source="puffin.jpg", save=True, conf=0.5, show=False)
코드를 실행해보면 'runs/detect/predict'에 예측 결과 이미지가 저장되어 있습니다.


모델의 predict가 잘 동작하는 것을 확인하였으니, Test 데이터에 적용해보겠습니다.
우선 Test 데이터에 대한 정보를 알아봅니다.
from glob import glob
test_image_list = glob('datasets/test/images/*')
print(len(test_image_list))
test_image_list.sort()
for i in range(len(test_image_list)):
print('i = ',i, test_image_list[i])
Test 데이터의 정보를 확인하였다면, 모델을 통해 Infer을 진행합니다.
results = model.predict(source='datasets/test/images/', save=True)
위에서와 마찬가지로 예측 결과는 'runs/detect/predict'에 저장되며, 아래와 같은 추가적인 과정을 통하여 예측 결과에 대한 정보와 파일을 관리할 수 있습니다.
import numpy as np
for result in results:
uniq, cnt = np.unique(result.boxes.cls.cpu().numpy(), return_counts=True)
uniq_cnt_dict = dict(zip(uniq, cnt))
print('\n{class num:counts} =', uniq_cnt_dict,'\n')
for c in result.boxes.cls:
print('class num =', int(c), ', class_name =', model.names[int(c)])import glob
detetced_image_list = glob.glob(('runs/detect/predict/*'))
detected_image_nums = len(detetced_image_list)
print(detected_image_nums)
print(detetced_image_list)import zipfile
import os
if not os.path.exists('detected_result/'):
os.mkdir('detected_result/')
print('detected_result dir is created !!!')
with zipfile.ZipFile('detected_result/detected_images.zip', 'w') as detected_images:
for idx in range(detected_image_nums):
detected_images.write(detetced_image_list[idx])