0. ABSTRACT
NLP분야에서 Transformer architecture는 사실상 표준이 되었지만, Vision에 대한 적용은 제한적이었습니다. 그러나 본 논문에서는 CNN에 대한 의존을 전혀 하지 않고, Transformer를 Image Patch Sequence에 직접 적용하는 방식으로 Image classification분야에서 우수한 성능을 발휘하는 것을 보여줄 것입니다. Large Dateset에 pre-training을 수행하고, mid or small Dataset에 transfer learning을 수행할 경우 sota cnn기반 모델들 보다 우수한 성능을 발휘하면서 학습에 필요한 계산량은 현저히 적어집니다.
1. INTRODUCTION
Self-attention 기반인 Transformer는 NLP에서 좋은 성능을 보이고 있습니다. Transformer는 Large text corpus로 부터 pre-train을 수행하고, smaller dataset에 fine-tuning하여 처리하는 접근 방식을 사용합니다. Transformer의 계산 효율성과 확장성(scalability) 덕분에 100억개가 넘는 parameter를 가지는 모델도 훈련이 가능하게 되었습니다.
이러한 이점을 갖고있는 Transformer에 영감을 얻어, 가능한 최소한의 수정을 통해 표준 Transformer를 이미지에 직접 적용하는 실험을 해보았습니다. 이를 위해 이미지를 Patch 단위로 분할하고, Patch의 sequence of linear embedding을 Transformer의 입력으로 제공합니다. Image Patch는 NLP에서의 token과 같은 방식으로 취급됩니다. supervised 방식으로 image classification task의 학습을 진행합니다.
정규화 없이 ImageNet과 같은 mid 크기의 dataset을 학습할 경우, ResNet보다 낮은 성능을 보여주었습니다. 그 이유는 Transfomer가 CNN은 갖고있는 inductive bias (inductive bias에 대한 설명)가 없다는 것입니다. 그러나 Large Dataset의 학습을 통해 inductive bias를 이길 수 있다는 것을 발견하였습니다. Lage Dataset으로 pre-train을 진행하고, 작은 Dataset에 transfer하면 SOTA를 달성할 수 있습니다
3. METHOD

모델 설계에서 가능한 한 Transformer를 따릅니다. 이러한 설정의 장점은 확장 가능한 NLP Transformer architecture와 효율적인 구현을 거의 바로 사용할 수 있다는 것입니다.
3-1. Vision Transformer (VIT)
- 우선 NLP의 Transformer가 Token embedding의 1-D Sequence를 입력으로 받으니, 입력이미지인 2D 이미지를 pxp크기의 Patch N개로 나눕니다. N개로 나눈 Patch를 flatten하고, 이를 LInear projection을 사용하여 D차원으로 mapping합니다. 이것을 patch embedding이라고 합니다.
- BERT의 [cls] 토큰과 비슷하게 learnable한 embedding을 patch embedding에 추가하고, 최종 transformer의 output에서의 z_L_0이 image representation y로 사용됩니다.
- position embedding은 위치 정보 유지를 위해 patch embedding에 추가(1-D position embedding 사용)
patch embedding + learnable cls embedding + Position embedding = Sequence embedding이 인코더 input으로 들어갑니다.
- Transformer encoder는 multi-head attention과 MLP의 반복 Layer로 구성됩니다. Layer Norm은 모든 block앞에 적용하고, 모든 block 뒤에는 residual connection이 적용됩니다. MLP는 비선형성을 가진 GELU를 가진 2개의 layer가 포함됩니다. 위 사진의 수식을 풀어서 설명한 것입니다.
Inductive bias
VIT는 CNN보다 inductive bias가 훨신 적습니다. MLP 레이어만 local, translationally equivariant를 가지며, self-attention layer는 global layer라서 CNN보다 inductive bias가 낮습니다.
Hybrid Architecture
원본 이미지 Patch의 대안으로 CNN Feature map을 활용합니다. Feature map은 이미 원본 이미지의 공간적 정보를 갖고 있으므로 Patch를 자를 때 1x1로 설정 가능합니다. Feature map을 flatten하고, 이를 linear projection한 patch embedding을 사용합니다.
3-2. Fine-Tuning and Higher Resolution
Large Dataset으로 pre-train을 진행하고, downstream task에 맞게 fine-tuning을 진행합니다. 이를 위해 pre-trained된 prediction head를 제거하고, zero-initialized된 DxK feedforward layer를 연결합니다.
더 높은 해상도의 이미지를 사용할 경우에는 patch 크기를 동일하게 유지하기에 sequence의 길이가 더 길어지게 됩니다. VIT는 임의의 시퀀스 길이를 처리할 수 있지만, pre-trained된 positioning embedding은 의미가 없어지게 됩니다. 따라서 원본 이미지의 위치에 따라 사전 학습된 positioning embedding의 2D interpolation을 수행합니다.
4. Experiments
4-1. Setup
Datasets
모델 확장성을 살펴보기 위해 1k 클래스와 1.3M 이미지가 포함된 ILSVRC-2012 ImageNet dataset
21k 클래스, 14M 이미지가 포함된 ImageNet-21k, 18k 클래스, 303M 고해상도 이미지가 포함된 JFT 사용
위와같은 3개의 Dataset으로 pre-train을 진행하고, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102등과 같은 benchmark tasks에 transfer 진행하여 실험을 진행하였습니다.
Model Variants
ViT 구성은 BERT에 사용된 구성을 기반으로 합니다. 모델 크기와 입력 패치 크기를 나타내기 위해 model이름 뒤에 간략한 설명을 추가했습니다. 예를 들어 ViT-L/16은 입력 패치 크기가 16x16인 Large 변형을 의미합니다. 논문의 저자인 Google Research Brain Team이 이전에 발표했던 SOTA 모델 Big Trasnformer(BiT)를 비교군으로 삼아 실험을 진행하였습니다.
Training & Fine-tuning
평가 지표는 Training set에 없는 클래스를 맞추는 문제에 대한 정확도를 나타내는 Few-shot accuracy와 Fine-tuning 후의 정확도를 나타내는 Fine-tuning accuracy를 사용하였습니다.
4-2. Comparison to SOTA

모든 Dataset에서 ViT-H/14가 가장 좋은 성능을 보여줍니다. 비교군인 BiT-L과 비교해봤을 때, 더 높은 성능을 보이면서 더 적은 시간이 걸린 것을 확인할 수 있습니다.
4-3. Pre-training Data Requirements
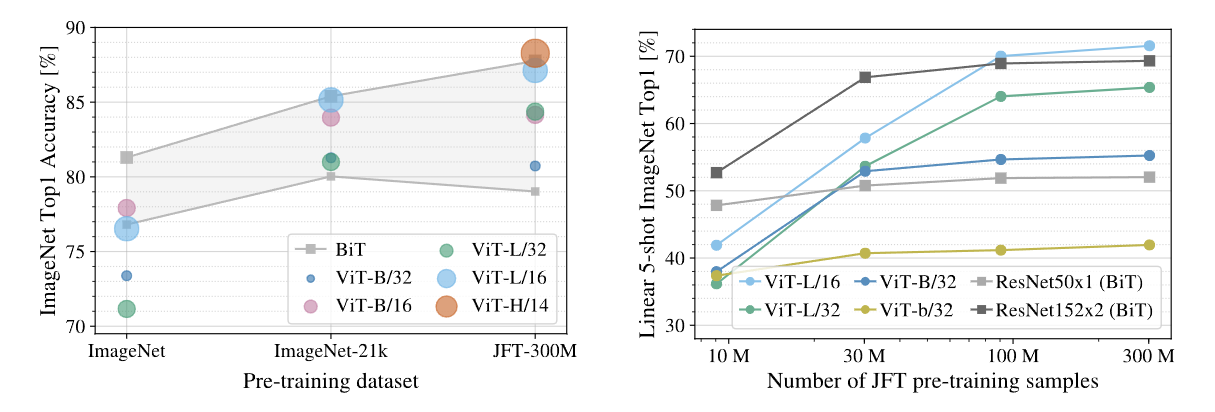
- 왼쪽 그래프를 보면, 크기가 큰 Dataset으로 pre-training 했을 때, ViT가 BiT보다 좋은 성능을 보이고, 크기가 작은 Dataset으로 pre-training 했을 때는 BiT가 ViT보다 좋은 성능을 보인다는 것을 확인할 수 있습니다.
- 오른쪽 그래프를 보면 적은 수의 data sample 경우, BiT가 ViT보다 좋은 성능을 보이지만, data sample의 수가 늘어날수록 ViT가 더 좋은 성능을 보이는 것을 확인할 수 있습니다. 이는 소규모 Dataset에서는 inductive bias가 있는 CNN 계열이 유용하지만, 대규모 Dataset의 경우에는 Transformer 데이터에서 직접 관련있는 패턴을 학습하기에 충분하고, 오히려 유리할수도 있다는 것을 보여줍니다.
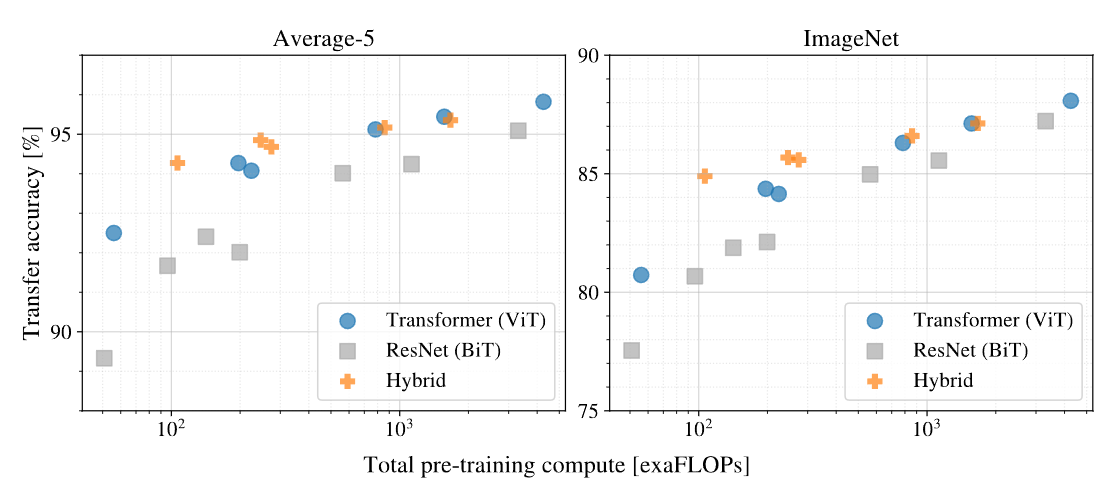
위의 표를 통해 같은 시간을 사용하였을 경우 ViT가 더 높은 성능을 보인 것을 확인할 수 있습니다. 또한 계산량이 적을 때는 Hybrid가 ViT보다 좋은 성능을 보이지만, 계산량이 많아질수록 역전되는 것 또한 확인할 수 있습니다.
4-5. Inspecting Vision Transformer
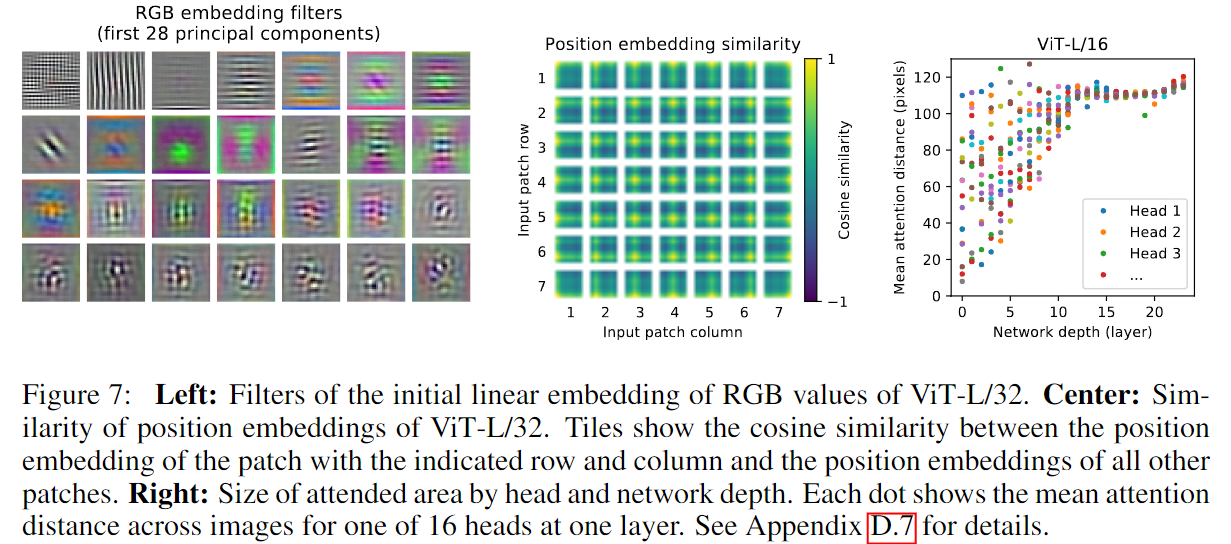
- 왼쪽 그림은 flatten된 patch를 patch embedding으로 변환하는 linear projection의 principal components를 분석한 것입니다. 이는 CNN의 저차원 Feature map과 유사한 것을 알 수 있고, CNN Filter 기능과 유사하다는 것을 알 수 있습니다.
- 가운데 그림은 patch간 position embedding 유사도를 시각화한 것입니다. 이를 통해 2D 이미지의 position대로 유사도가 높다는 것을 확인할 수 있습니다.
- 오른쪽 그림은 ViT의 Network Depth별로 Mean attention distance를 시각화한 것입니다. 이를 통해 얕은 Depth에서도 attention mechanism을 통해 이미지 전체의 정보를 통합하여 사용하는 것을 확인할 수 있습니다.

또한 모델이 classification에 의미적으로 관련성이 있는 이미지 영역에 attention한다는 것을 발견하였습니다.
5. Conclusion
이미지의 Inductive bias를 architecture에서 사용하지 않고, 이미지를 patch sequence로 해석하고 NLP에 사용되는 표준 Trasnformer 인코더로 처리합니다. 이는 대규모 데이터셋에 대한 pre-training과 결합하면 아주 잘 작동하는 것을 확인할 수 있었습니다. 따라서 Vision Transformer는 많은 image classification dataset에서 기존 SOTA model를 능가하고, 심지어 사전 학습 비용이 저렴합니다.
남은 과제로는 ViT를 Detection분야와 Segmentation분야에 적용하는 것과 scaling을 통한 ViT의 성능 향상이 남았습니다.
'Deep Learning > Vision' 카테고리의 다른 글
| R-CNN (0) | 2023.11.02 |
|---|---|
| Pose Estimation (0) | 2023.11.01 |
| U-Net (2015 - Convolutional Networks for Biomedical Image Segmentation) (0) | 2023.10.04 |
| FCN (2015 - Fully Convolutional Networks for Semantic Segmentation (0) | 2023.09.27 |
| EfficientNet (2019 - Rethinking Model Scaling for Convolutional Neural Networks) (0) | 2023.09.22 |






댓글