마지막 강의인 16강에서는 Adversarial Example에 대해서 배웁니다.

2013년부터 NN 성능은 인간 수준까지 끌어올렸습니다. Nueral Network가 좋은 성능을 이끌어낼 수 있었던 것은 CNN의 사용이 큰 지분을 차지합니다. 그러나, 입력 이미지의 약간의 변동을 주는 것(Adversarial Attack)으로 Nueral Network를 헷갈리게 만들어 잘못된 출력값을 내뱉게 공격이 가능하다는 약점이 발견되었습니다.
위 슬라이드를 보면 인간의 눈으로 봤을 때, 왼쪽과 오른쪽의 이미지는 둘 다 판다의 이미지라고 판단하지만, Neural Network의 입장에서는 왼쪽 이미지에서 noise filter를 더한 오른쪽 이미지는 긴팔 원숭이라고 판단을 하게 됩니다. 인간의 눈으로는 각 이미지의 출력값에 대해 변화가 없는것 처럼 보이지만, Numpy로 이미지의 값을 확인할 경우 미세한 변화가 있는 것을 확인할 수 있고, 오른쪽 이미지와 같이 미세한 변화로 Neural Network를 속이는 이미지들을 Adversarial Examples라고 합니다.
처음에는 Adversarial Examples들은 Overfitting 때문에 발생한다고 생각하였습니다. Neural Network의 decision boundary가 Overfitting으로 인해 복잡하게 되어 있어 잘못된 decision boundary가 생기고, 이것이 Nueral Network를 헷갈리게 만들 수 있다는 것입니다. 하지만 이는 잘못된 판단이었습니다. 1장의 Adversarial Example이 여러 개의 Neural Network를 헷갈리게 만드는 결과를 가져왔고, 모든 Nueral Network가 동일하게 잘못된 예측값을 출력하였습니다. 그리하여 Neural Network의 Overfitting으로 인해 생긴 잘못된 decision boundary가 문제가 아님을 판단 수 있었습니다.

다음으로는 과도한 Linearity가 Adversarial Examples를 발생하게 만들었다는 생각을 하게 됩니다. 대부분의 DNN은 Network의 parameters와 output값은 Non-Linear한 형태를 갖고 있지만, Input과 Output 사이의 Mapping이 piecewise linear한 형태를 갖고있어 부분적으로는 Linear한 형태를 갖게 됩니다. 이러한 형태는 DNN이 Linear한 영역에서는 예측가능하고 해석 가능한 경향을 가지지만, 전체적으로 봤을 때, 복잡한 Non-linear동작을 수행하는 것을 의미합니다. 그렇다면 DNN의 piecewise linearity가 Adversarial Examples과 어떤 관계가 있을까요? DNN이 piecewise linearity하다는 것은 Network가 특정 구간에서 입력값에 대해 선형적으로 반응하는 성질을 갖고 있음을 시사합니다. 이러한 성질은 인간의 눈으로는 알아채기 힘든 매우 작은 입력값의 변화가 출력값에 있어 큰 변화를 일으킬 수 있습니다.
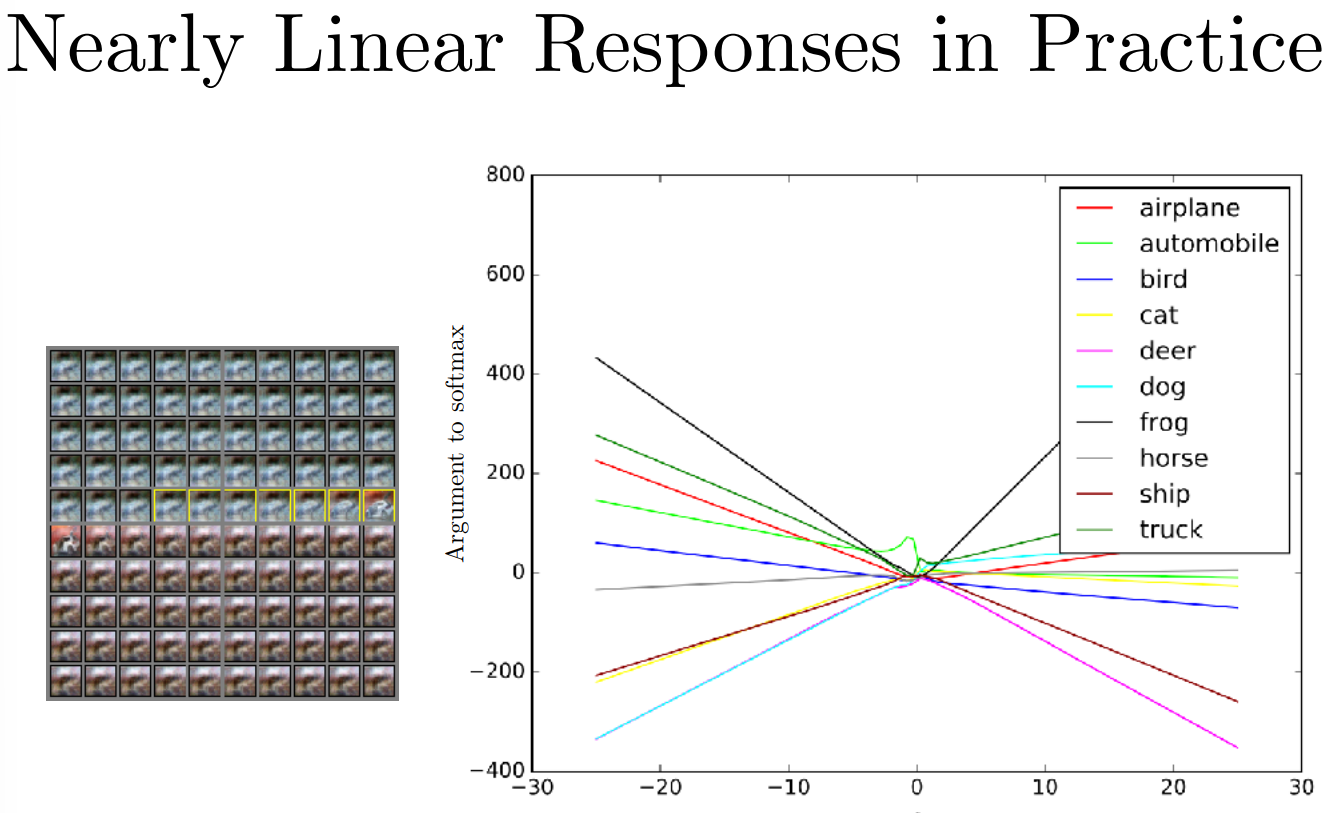
오른쪽 plot은 clear한 자동차 이미지에 특정한 방향 벡터 ϵ 값을 더하거나 빼는 연산을 해주고, 각 class에 대한 예측 확률을 보여주는 plot입니다. 해당 plot에서 더하거나 빼준 방향 벡터는 frog class에 대한 것이며, frog class 방향 벡터 연산을 수행하지 않은 0인 지점에서는 truck class에 대한 예측값이 가장 높은 것을 볼 수 있지만, frog class에 대한 방향 벡터 연산을 수행한 지점에서는 frog class의 예측 확률이 linear하게 변화하는 것을 볼 수 있습니다.

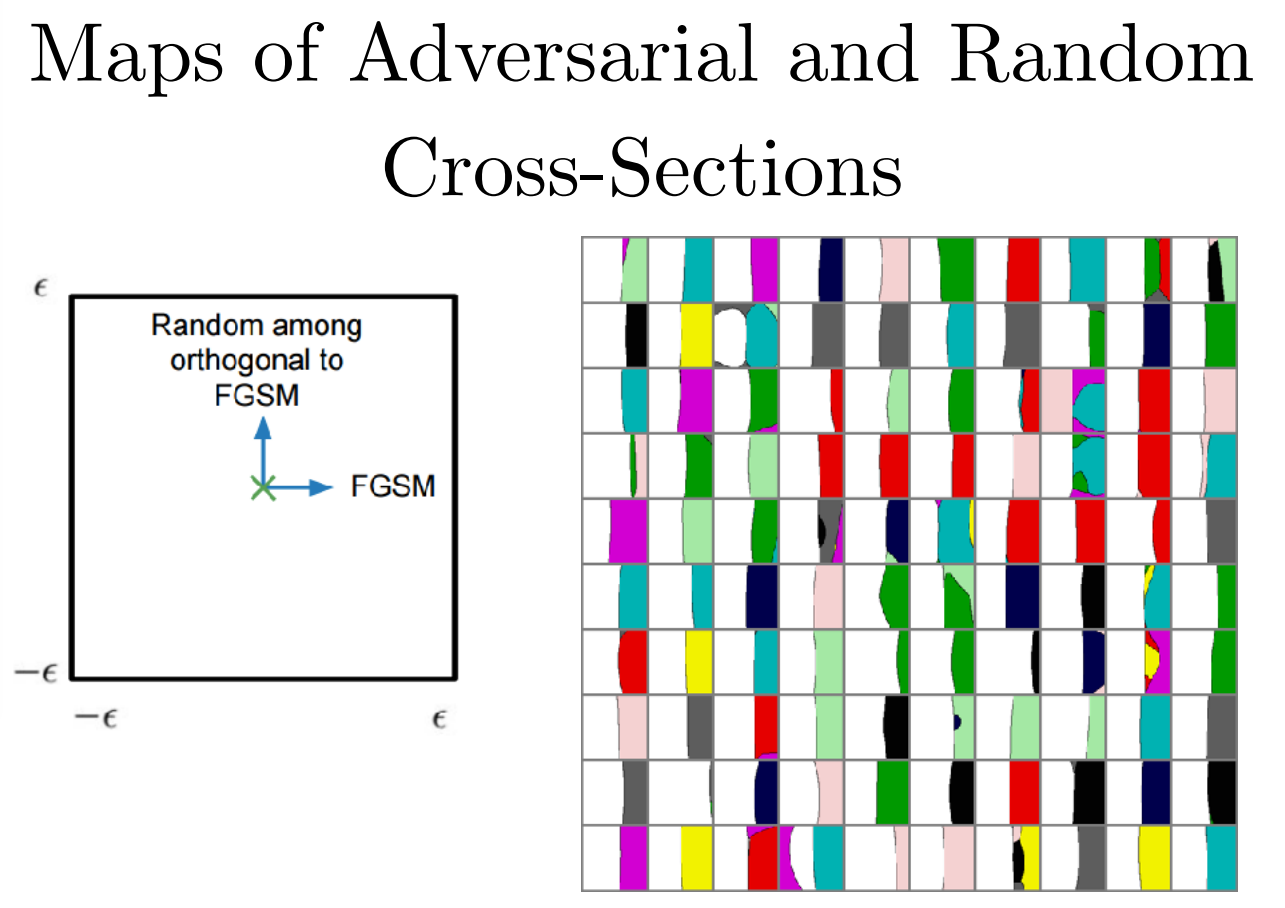
특정 class의 방향 벡터를 찾는 것은 왼쪽 슬라이드에 나온 것처럼 FGSM을 사용하면 쉽게 찾을 수 있고, CIFAR-10 데이터셋을 이용하여 실험해본 결과는 오른쪽 슬라이드와 같습니다. 흰색으로 칠해진 영역은 올바른 예측을 수행한 것이고, 색칠된 영역은 틀린 예측을 수행한 것인데, FGSM을 통해 찾은 방향 벡터 연산을 적용하면 잘못된 예측을 수행한다는 것을 확인할 수있고, FGSM을 통해 찾은 방향 벡터가 orthogonal(직교)한 방향으로 발생하는 것은 아닌것 또한 확인할 수 있습니다.

Adversarial attack을 막기 위해 Network의 parameter를 숨겨서 Network에 대한 FGSM 적용을 막더라도 해당 Network가 어떻게 예측을 수행하는지 모방하도록 학습한 Network를 이용하여 찾은 Adversarial Examples은 해당 Network에 취약하게 적용될 가능성이 높다고 합니다.
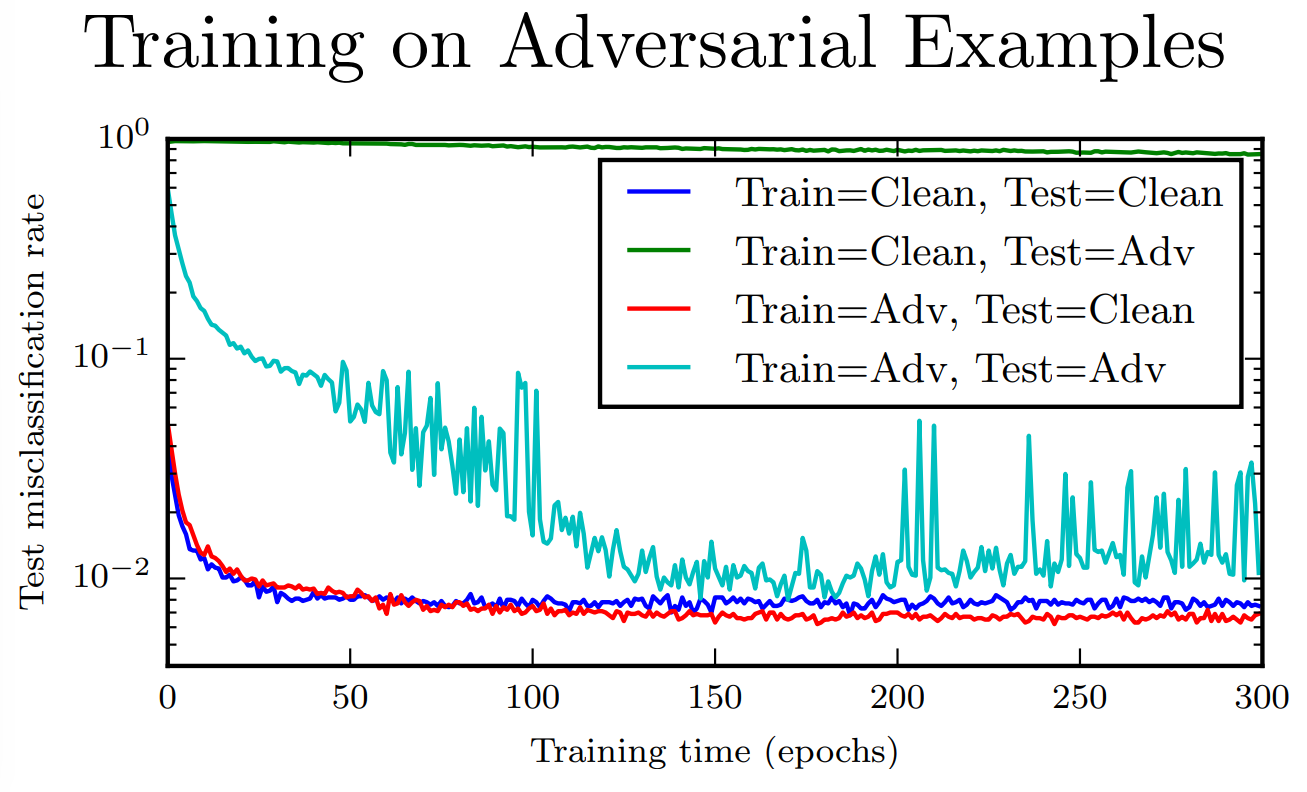
Adversarial attack을 막을 수 있는 현실적인 방법은 모델이 Adversarial Examples도 training하는 것이라고 합니다. 위 슬라이드의 그래프를 보면 Adversarial Examples를 학습하고, Clean한 이미지로 test를 진행한 Red Graph가 잘 작동되는 것과 regularization효과로 성능의 개선도 이루어진 것을 확인할 수 있습니다.
'Lecture > CS231n' 카테고리의 다른 글
| CS231n 13강 (0) | 2024.02.07 |
|---|---|
| CS231n 11강 (0) | 2024.02.06 |
| CS231n 10강 (0) | 2024.02.01 |
| CS231n 9강 (0) | 2024.02.01 |
| CS231n 8강 (0) | 2024.02.01 |






댓글